

数据高可用的含义主要包括以下几个方面:
1、数据持久性
2、数据可访问性
3、数据一致性
博主按:这里不详细解释上述具体概念了,可以顾名思义,如果你了解它们我就不用解释,如果你不懂那说明你不需要了解,无需解释。
大多数时候,为了保证数据的高可用性,网站通常会牺牲数据一致性这一重要指标,尤其是对于大型网站。
CPA原理:一个提供数据服务的存储系统无法同时满足数据一致性(C),数据可用性(A)和分区耐受性(P),三者是三角关系。
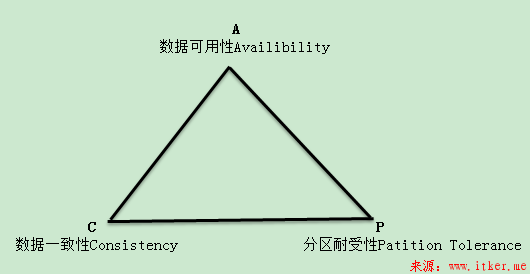
大型网站的数据规模扩张迅速,所以可伸缩性(P)是必不可少的。而机器数量变得庞大以后,网络和服务器的故障就会发生频繁,分布式处理系统的高可用是要保证的,所以大型网站会强化分布式存储系统的可用性(A)和伸缩性(P),而在某种程度上放弃一致性(C),故障恢复和集群扩容等场景是导致数据不一致的主要原因,可以在某种程度上进行补偿和纠错,尽可能的降低这种不一致性。
所以,对于可伸缩的分布式应用系统来说,CPA原理具有重要的意义,在系统设计开发过程中,不恰当的迎合各种需求,试图打造一个完美的系统,很容易使设计进入两难境地,后患无穷。
题外话:可用性关系到一家公司的生死存亡,关系到IT团队的绩效升迁,IT团队对架构做了很多优化,甚至对代码做了重构,对性能、扩展性、伸缩性做了很多改善,但别人未必能够直观的感受到,也许你的领导不知道你做的这些事情意义何在,但如果你负责的网站除了重大故障,CEO都会知道你的名字,公司与人一样都是先求生存再求发展,保证网站的可用性任重而道远!

©️公众号:思考者文刀
- 上一篇: 一致性Hash算法在分布式缓存中的运用
- 下一篇: 「砥砺阅读」之十九:《暗访十年(四)》













评论
顾修博客
回复好吧,这文章,我看不懂