

Kafka是一个分布式的、高吞吐的、基于发布/订阅的消息系统。利用kafka技术可以在廉价PC Server上搭建起大规模的消息系统。Kafka具有消息持久化、高吞吐、分布式、实时、低耦合、多客户端支持、数据可靠等诸多特点,适合在线和离线的消息处理。是用Scala开发的,起初应用于 LinkedIn ,作为一种简化Hadoop 从 Apache Flume提取消息的方案
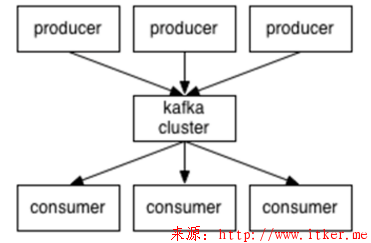
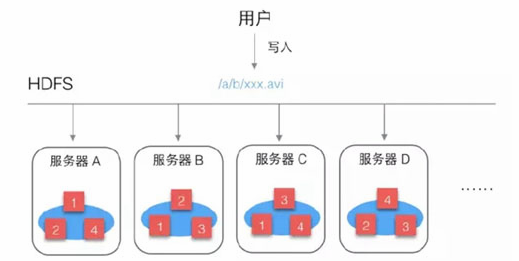
一个典型的Kafka体系架构包括若干Producer(可以是服务器日志,业务数据,页面前端产生的page view等等),若干broker(Kafka支持水平扩展,一般broker数量越多,集群吞吐率越高),若干Consumer (Group),以及一个Zookeeper集群。Kafka通过Zookeeper管理集群配置,选举leader,以及在consumer group发生变化时进行rebalance。Producer使用push(推)模式将消息发布到broker,Consumer使用pull(拉)模式从broker订阅并消费消息.
partition是实际物理上的概念,而topic是逻辑上的概念,主题(topic)和日志(log)设置是kafka一大特色,一个kafka集群可以创建多个topic, 每个topic都相当于一个消息队列,这就意味着可以将不同格式的数据发布到不同的topic中,减小消费这些数据时的逻辑难度,kafka通过partition和顺序读写磁盘的方式达到很高吞吐量。
每一个partition 都会有一个服务器来作为领导者(leader), 另外一个或者多个服务器(server)来作为跟随者(follower),leader会处理所有的读写请求,而follower则会从leader那里备份数据, 如果一个leader失败了, 其它的follower会自动选举一个成为一个新的leader, 所以对于一个server来说,他可能是某些partition下的leader, 而对于另外一些partition来说则是follower,这样设计可以将负载更好均衡。
100k/sec性能往往是人们选择 Apache Kafka的关键驱动力。它的实现很大依赖开发者能够写出聪明的消费者代码。

- 上一篇: Hadoop之MapReduce
- 下一篇: 「砥砺阅读」之十七《未来简史》











评论
imitker
回复test