

2003年Google发表《Google File System》,即GFS集群,主要包括Master node和Chunkservers。在2004年Google发表论文并引入MapReduce的概念,两位创始人谢尔盖布林和拉里佩奇就是凭借其在斯坦福大学时期发明的MapReduce算法解决了大规模网页搜索中的并行化和权重问题而成立了google公司,并首先改写了其搜索引擎中的Web文档索引处理系统,到目前为止,Google公司内有上万个各种不同的算法问题和程序都使用MapReduce进行处理。
MapReduce可以理解为把一堆杂乱无章的数据按照某种特征归纳起来,然后处理并得到最后的结果。Map面对的是杂乱无章的互不相关的数据,它解析每个数据,从中提取出key和value,也就是提取了数据的特征。经过MapReduce的Shuffle阶段之后,在Reduce阶段看到的都是已经归纳好的数据了,在此基础上我们可以做进一步的处理以便得到结果。
"MapReduce改变了我们组织大规模计算的方式,它代表了第一个有别于冯·诺依曼结构的计算模型,是在集群规模而非单个机器上组织大规模计算的新的抽象模型上的第一个重大突破,是到目前为止所见到的最为成功的基于大规模计算资源的计算模型。"《Data-Intensive Text Processing with MapReduce》
2006年2月,Doug Cutting等人在Nutch项目上应用GFS和 MapReduce思想,并演化为Hadoop项目。下图就是Doug Cutting的照片,是不是帅的惊天地泣鬼神。

MapReduce可以说是Hadoop的精华所在,是当代用于数据处理的最优的编程模型。MapReduce从名称上面可以看到分为Map(映射)和Reduce(归纳)两个部分。其思想类似于先分后合,Map对与数据进行抽取转换,Reduce对数据进行汇总。其中需要注意的是Map任务将输出结果存储在本地磁盘,而不是HDFS。大致过程如下图:
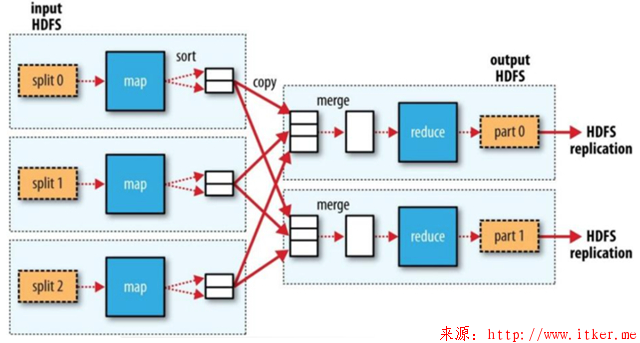
在执行每个map task 和 reduce task的时候,有以下要点:
1、在整个Map-Reduce阶段,无论Map方法中执行什么逻辑,最终都是要把输出写到磁盘上。
2、如果没有Reduce作业,只有Map阶段,则直接输出到HDFS上。
3、如果有Reduce作业,则每个Map方法的输出在写磁盘前先在内存中缓存。
4、每个Map Task都有一个环状的内存缓冲区,存储着Map的输出结果,默认100M,每次当缓冲区快满的时候由一个独立的线程将缓冲区的数据以一个溢出文件的方式存放到磁盘,当整个Map Task结束后再对磁盘中这个Map Task产生的所有溢出文件进行合并处理,生成已分区且已排序的输出文件。然后等待Reduce Task来拉数据。
上述1-4说的就是MapReduce中赫赫有名的Shuffle过程。
以下是MapReduce过程的一个实际运用过程:


- 上一篇: Hadoop之HBase&Hive
- 下一篇: Hadoop之kafka











评论