

「学习笔记」深入理解Hadoop HDFS的写入&读取机制
博主按:要理解以下内容,需要掌握namenode,datanode、元数据等概念及HDFS的基本原理。HDFS(Hadoop Distribute File System)是一个分布式文件系统,是Hadoop的重要成员。
一、HDFS数据写入机制
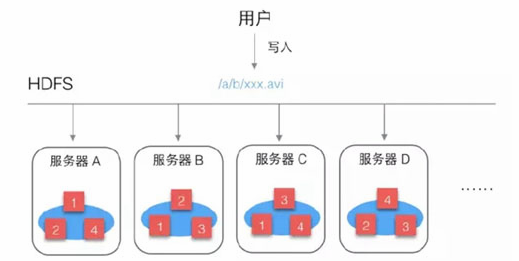
向HDFS中写入文件时,是按照块儿为单位的,Client会根据配置中设置的块儿的大小把目标文件切为多块,例如文件是300M ,配置中块大小值为128M,那么就分为3块儿。
具体写入流程:
(1)Client向Namenode发请求,说想要上传文件
(2)NameNode会检查目标文件是否存在、父目录是否存在,检查没有问题后返回确认信息
(3)Client再发请求,问第一个block应该传到哪些DataNode上
(4)NameNode经过衡量,返回3个可用的DataNode(A,B,C)
(5)Client与A建立连接,A与B建立连接,B与C建立连接,形成一个Pipeline
(6)传输管道建立完成后,Client开始向A发送数据包,此数据包会经过管道一次传递到B和C
(7)当第一个block的数据都传完以后,client再向NameNode请求第二个block上传到哪些DataNode,然后建立传输管道发送数据
就这样,直到Client把文件全部上传完成
二、HDFS数据读取机制
(1)Client把要读取的文件路径发给Namenode,查询元数据,找到文件块所在的DataNode服务器
(2)Client知道了文件包含哪几块儿、每一块儿在哪些DataNode上,就选择那些离自己近的DataNode(在同一机房,如果有多个离着近的,就随机选择),请求建立Socket流从DataNode获取数据
(3)Client接收数据包,先本地缓存,然后写入目标文件直到文件读取完成
三、NameNode机制
通过对HDFS读写流程的了解,可以发现NameNode是一个很重要的部分,它记录着整个HDFS系统的元数据,这些元数据是需要持久化的,要保存到文件中。
NameNode还要承受巨大的访问量,Client读写文件时都需要请求NameNode,写文件时要修改元数据,读文件时要查询元数据。
为了提高效率,NameNode便将元数据加载到内存中,每次修改时,直接修改内存,而不是直接修改文件,同时会记录下操作日志,供后期修改文件时使用。
这样,NameNode对数据的管理就涉及到了3种存储形式:
内存数据
元数据文件
操作日志文件
NameNode需要定期对元数据文件和日志文件进行整合,以保证文件中数据是新的,但这个过程很消耗性能,NameNode需要快速地响应Client的大量请求,很难去完成文件整合操作,这时就引入了一个小助手SecondNameNode。
SecondNameNode会定期从NameNode中下载元数据文件和操作日志,进行整合,形成新的数据文件,然后传回NameNode,并替换掉之前的旧文件。
SecondNameNode是NameNode的好帮手,替NameNode完成了这个重体力活儿,并且还可以作为NameNode的一个防灾备份,当NameNode数据丢失时,SecondNameNode上有最近一次整理好的数据文件,可以传给NameNode进行加载,这样可以保证最少的数据丢失。


- 上一篇: 「学习笔记」MVC框架Structs
- 下一篇: 「砥砺阅读」之十二《谁在投机中国》













评论
QueenslandAssignment
回复楼主的主题很好,我很喜欢。
imitker
回复@QueenslandAssignment 谢谢,请多指教
以太坊
回复没有留言板,就在这反馈点用户体验,标签那个球状,看着挺花哨,但一点都不实用,鼠标放上乱跑,透明度还高,看不清哪个是哪个,估计你是在秀技术(开个玩笑)
imitker
回复@以太坊 感谢你的建议,已经调整了,欢迎提意见
以太坊
回复@imitker 现在很漂亮,果然大神,调整个效果就是分分钟的事。
imitker
回复@以太坊 :)